Поиск для сайта на базе SharePoint 2013. Часть 2. Адаптация сайта
Часть 1: robots.txt, sitemap.xml и другие особенности
Часть 2. Адаптация сайта
Продолжая тему построения поиска на базе SharePoint 2013 для сайта, сегодня я расскажу как можно оптимизировать сам сайт для индексирования его силами SharePoint 2013 Server.
Сайт
Какая технология использовалась для создания сайта (HTML, PHP, Classic ASP, ASP.NET, ...) - значения не имеет. Единственное требование - возвращать HTML-код, а не использовать какой-нибудь Flash.
Идентификация краулера
Что "научить" сайт правильно реагировать на краулер поисковика SharePoint 2013, первое что понадобиться - уметь этот краулер идентифицировать. Краулер SharePoint 2013 при запросе содержимого указывает следующий User-Agent (по умолчанию):
Mozilla/4.0 (compatible; MSIE 4.01; Windows NT; MS Search 6.0 Robot)
Значение это краулер берет из реестра и его можно изменить. Например, для того, чтобы отличать родной краулер от других основанных на SharePoint 2013. Путь в реестре следующий:
HKLM\SOFTWARE\Microsoft\Office Server\15.0\Search\Global\Gathering Manager\UserAgent
Помимо заголовка User-Agent в запросе присутствует ещё один - From. В качестве значения он содержит адрес электронное почты, указанный в панели администрирования поиска.
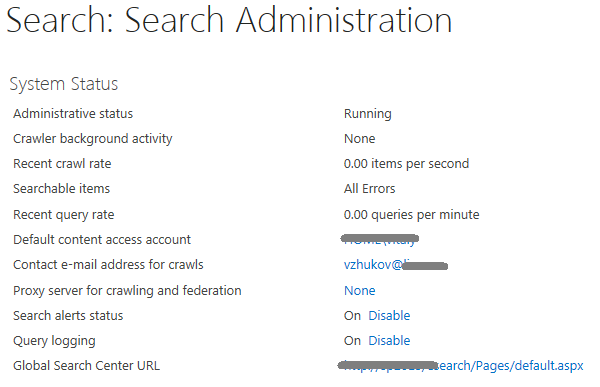
Если менять значение ключа в реестре менять не хочется, а отличать свой SharePoint-краулер от чужих надо - можно положиться на него. Вот пример запроса краулера SharePoint 2013:
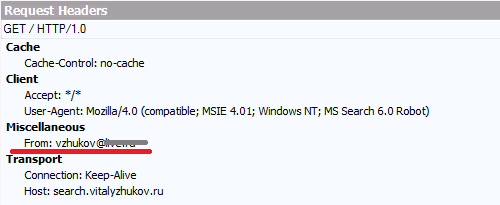
Пример идентификации
В случае, если сайт сделан на ASP.NET, то в codebehind можно реализовать какое-нибудь булево свойство IsFriendlyCrawler, которое будет возвращать True в случае, если страница запрашивается своим краулером, и False - в противном случае:
public bool IsFriendlyCrawler
{
get
{
var request = Page.Request;
var header = request.Header;
var userAgent = header["User-Agent"]
var fromMail = header["From"]
}
}
Этот подход поможет сделать некоторый контент вашего сайта доступным только для внутреннего поиска, а также создавать search-based решения.
Заголовок страницы
При индексации сайта SharePoint 2013 создает управляемые свойства для каждого meta-тега в заголовке страницы. На странице демо-сайта search.vitalyzhukov.ru, я добавил следующий meta-тег:
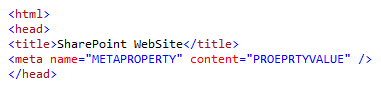
После индексации в схеме поиска будут добавлены следующие свойства:
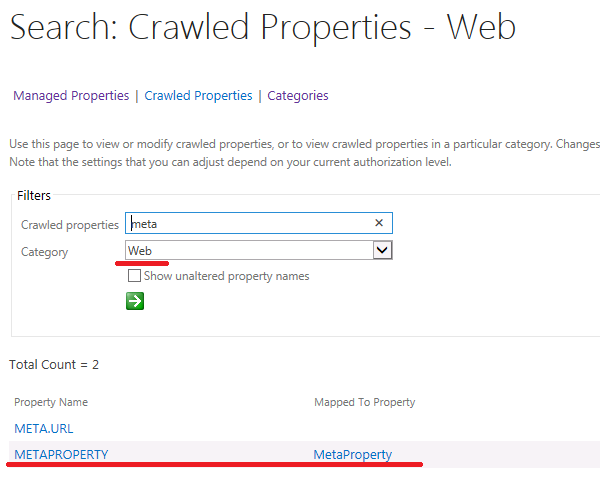
Их значения также можно использовать для формирования результатов или учета при ранжировании.
IFrame
Если на вашем сайте используются фреймы, то полезно будет знать то, как краулер SharePoint осуществляет их обход: он индексирует их ровно как и ссылки, т.е. контент вида
<ifram src="framsource.aspx"></iframe>
будет проиндексировано как если бы это была обычная ссылка
<a href src="framsource.aspx"></a>
Учитывайте это, чтобы в результаты поиска не попадали ссылки, не предназначенные для непосредственного просмотра пользователями.







