SharePoint 2013 Enterprise Search. Часть 1. Логическая архитектура
Часть 1. Логическая архитектура поиска в SharePoint 2013
Часть 2. Создание дополнительного обработчика контента для поиска в SharePoint 2013
Поиск в SharePoint 2013 является одним из основных инструментов доступа к данным. В новой версии две линейки поисковых продуктов (SharePoint Search и FAST Search) стали единым целым. Аналогичная ситуация, когда рядом стоящий продукт (PerformancePoint Server), базирующийся на SharePoint, стал с ним единым целым произошла в SharePoint 2010, что является безусловным признаком успешности продукта.
В этом посте я постараюсь описать, что есть поиск в SharePoint 2013, из чего он состоит и чем отличается от поиска в SharePoint 2010.
Логическая архитектура
Сперва диаграмма логической архитектуры поиска в SharePoint 2013 (с сайта download.microsoft.com):
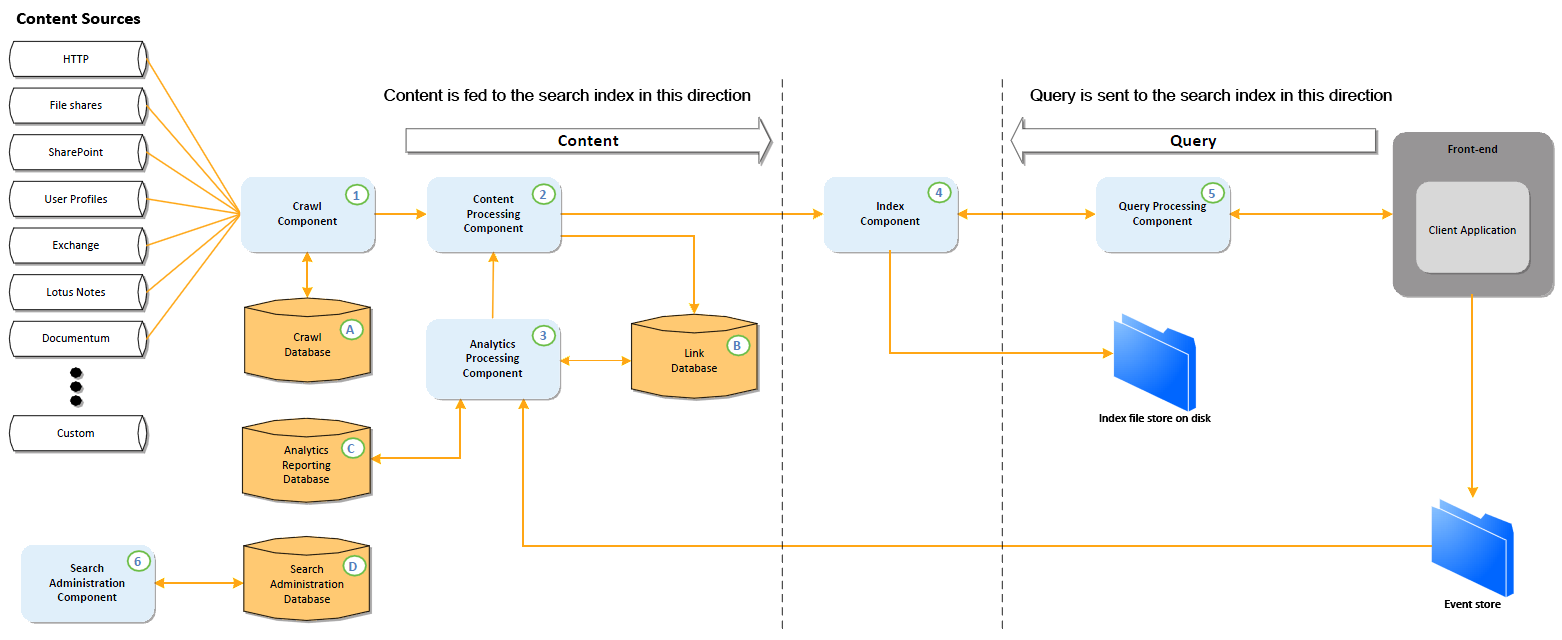
И теперь по пунктам:
(1) Crawl Component
Crawler обеспечивает извлечение данных, подлежащих индексации. При этом никакой обработкой он не занимается. Crawler использует различные коннекторы для извлечения данных и мета-данных с ними связанными. Этот недоCrawler просто передает извлеченные данные на обработку компоненту обработки контента (Content Processing Component).
(2) Content Processing Component
После того, как Crawler извлек данные, они передаются основному компоненту поиска - обработчику контента. Здесь происходит обработка данных, включающая в себя:
- обработка формата файла (поддержка iFilter'ов осталась) для преобразования данных и получения артефактов, которые можно использовать для индексации (почти всегда это означает получение текста из любого формата данных с помощью соответствующего ему iFilter'а);
- лингвистический анализ данных для определения языка;
- генерация фонетических форм названия;
- запись информации о ссылках в соответствующую БД.
Помимо этого в этом компоненте происходит дополнительная кастомная обработка данных с использованием WCF-сервисов.
В SharePoint 2010 обработка файлов была основана на их расширении, дополнительная обработка данных была реализована с помощью расширенной обработки содержимого (Advanced Content Processing).
(3) Analytics Processing Component
Этот компонент предназначен для анализа обработанных данных (ранжирование и расчет рекомендаций поиска).
В SharePoint 2010 за это отвечала служба Web Analytics, которая в SharePoint 2013 стала частью поиска.
(4) Index Component
Компонент используемый с двух сторон: для записи обработанных данных в индекс и для извлечения данных из индекса по запросу.
Также отвечает за перемещение уже проиндексированного контента (перемещение контента не влияет на его релевантность, если другое явно не прописано в модели ранжирования).
(5) Query Processing Component
Query Processing Component отвечает за подготовку поискового запроса, получаемого из front-end среды, для передачи его Index Component. Здесь происходит определение языка запроса, проверка орфографии, поиск словоформ для формирования более полного запроса (слова в поисковом запросе могут быть заменены на более часто употребляемые синонимы). Запрос, адаптированный для индекса, отправляется в Index Component, а полученный результат снова анализируется и адаптируется уже для возврата его во front-end.
(6) Search Administration Component
Компонент администрирования отвечает за топологию поиска и взаимодействие компонентов поиска.
В SharePoint 2010 поиск был достаточно мощным инструментом для построения решений и решения различных задач. А в SharePoint 2013 он по праву может стать основным инструментом извлечения данных.
























































































